You've probably heard that columnar analytical databases are able to query data so much faster than traditional row-based databases like PostgreSQL, Oracle or MySQL. But how much? 10 times faster?, 100 times faster?
First of all, it makes complete sense that there's a sensible difference in performance between OLAP and OLTP databases.
The goal of PostgreSQL is to work reliably under the pressure of hundreds of clients executing thousands of transactions per second. You can be sure that, if the transaction ends, data will be ready for the next query.
Analytics DBMS are designed for speed, and one shouldn't expect the same guarantees as with PostgreSQL. You should expect... speed.
I did a small experiment with a synthetic dataset I created for the PyCon Spain '22 workshop. It simulates records of roulette bets in an online casino. The dataset has 277M rows, and the CSV containing the data will take 28GB of your disk.
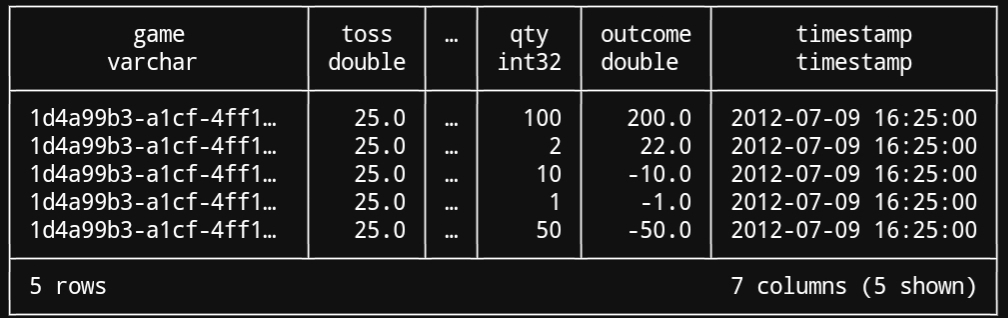
The query is designed to crash naive query engines, with a CTE and two nested aggregations:
with by_nplayers as (
SELECT
max(toss) as toss,
count(*) as qty,
count(*) as nplayers,
game
FROM
boards
GROUP BY
game
)
select
sum(qty) as qty,
toss,
nplayers
from
by_nplayers
group by
toss, nplayers
order by
nplayers, toss desc
Here are the results for postgresql

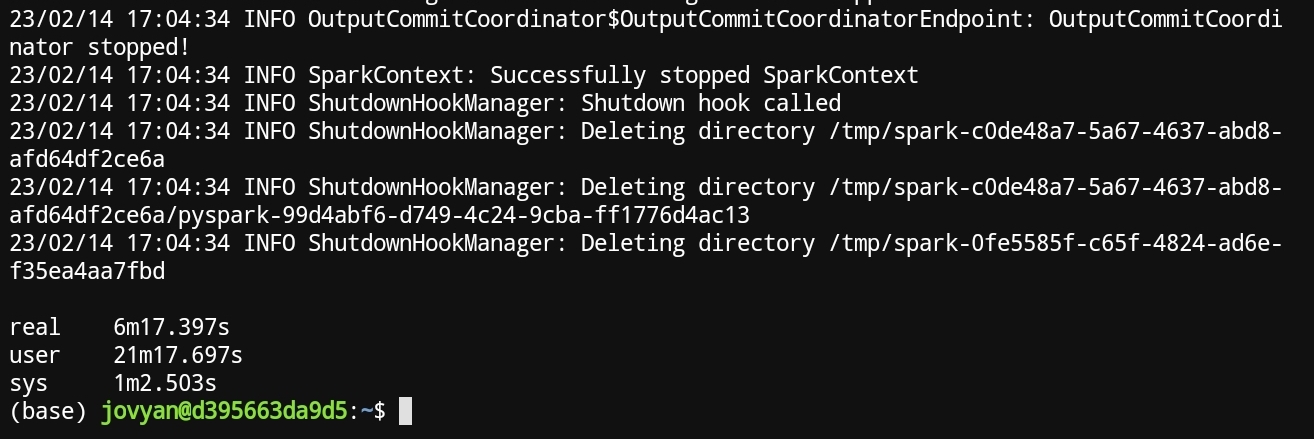
Here the results for Spark. For some reason Spark insisted in creating more than 200 partitions 🤷.
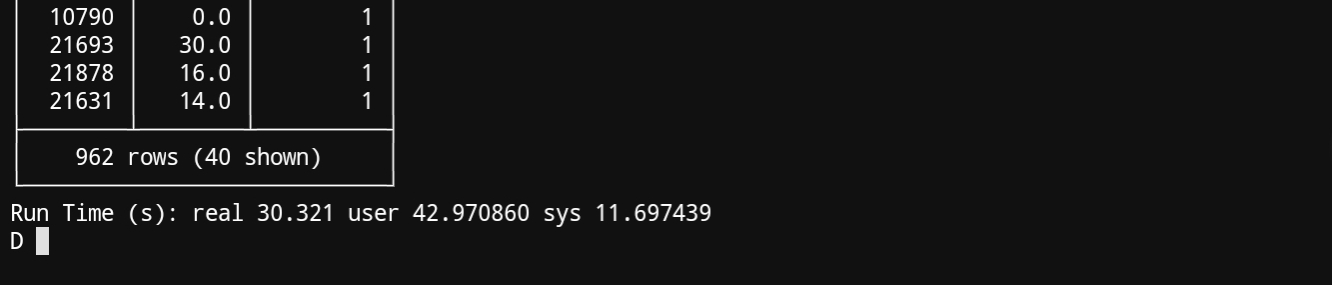
Here the results for duckdb
And finally clickhouse
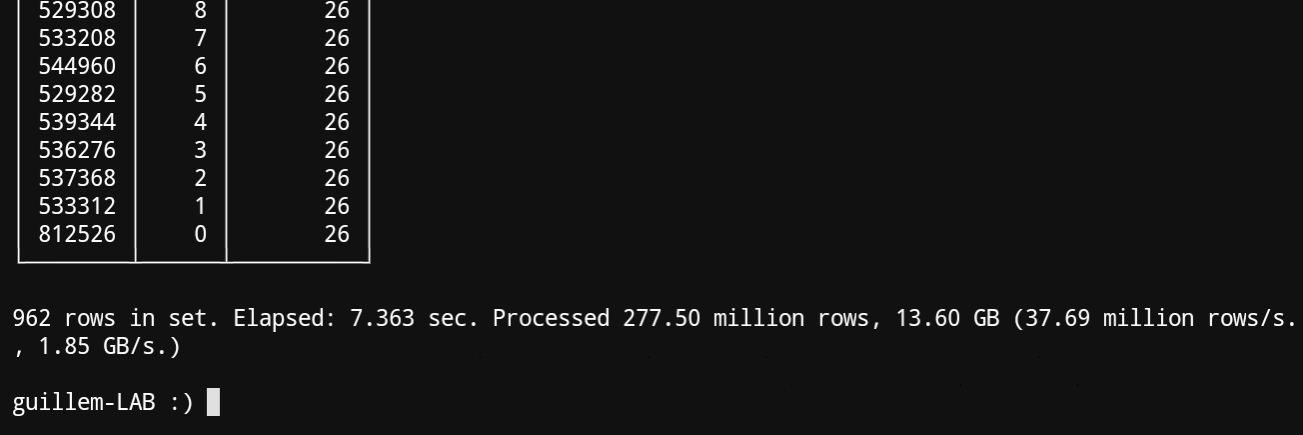
Additionally, clickhouse used rougly 3.5 GB of memory to execute the query, while duckdb ran with a limitation of 4GB RAM memory. The limitation was followed, since the container used for these tests would have crashed if it weren't.
Clickhouse was 88 faster than PostgreSQL.
This two-order-of-magnitude-faster operation is an obvious enabler. This means that someone can attach gigabyte-sized datasets to dashboards without the need of pre-aggregating data. I've needed to create hundreds of ETL processes during my career for the sole purpose of feeding some dashboard that otherwise would have taken hours to plot the results. You can still do that with cloud-hosted distributed databases like Snowflake or Redshift but at a relevant cost.