17 KiB
How data is stored
How data is stored physically
Enterprise data systems are heavily distributed because large corporations are distributed in nature: a chain of grocery stores consists of a set of locations that are relatively independent from each other. Distributed systems, when designed properly, are very robust in nature. If every location can operate independently items can be sold even under a major system failure, like losing the connection between a site and the central database that stores the available stock for each item. But at the same time, disconnecting each site from a central information repository is a challenging data engineering problem.
!!! info
A key property for data stored in an enterprise context is consistency, which is very difficult to guarantee when data is spreaded across multiple nodes in a network that can be faulty at times.
The CAP theorem, sometimes called Brewer's theorem too, is a great tool to provide some theoretical insight about distributed systems design. The CAP acronym stands for Consistency, Availability and Partition tolerance. The theorem proves that there's no distributed storage system that can offer these three guarantees **at the same time**:
1. Consistency, all nodes in the network see the exact same data at the same time.
2. Availablity, all nodes can fetch any piece of information whanever they need it.
3. Partition tolerance, you can lose connection to any node without affecting the integrity of the system.
Relational databases like need to be consistent and available all the time, this is why there aren't distributed versions of PostgreSQL where data is spreaded (sharded) across multiple servers in a network. If there are multiple nodes involved, they are just secondary copies to speed up queries or increase availability.
If data is spreaded across multiple nodes, and consistency can't be traded off, availability is the only variable engineers can play with. Enterprise data systems run a set of batch process that synchronize data across the network when business operation is offline. When these batch processes are running data may be in a temporary inconsistent state, and the database cannot guarantee that adding new data records is a transaction. The safest thing to do in that case is to blocking parts of the database sacrificing availablity.
This is why the terms transactional and batch are used so often in enterprise data systems. When a database records information from some actual event as it happens, like someone checking out a can of soup at a counter, that piece of information is usually called a transaction, and the database recording the event a transactional system because its primary role is to record events. The word transactional is also used to the denote that integrity is a key rquirement: we don't want that any hiccup in the database mistakingly checks up the can of soup twice because the first transaction was temporarily lost for any reason. Any activity that may disrupt its operations has to be executed while the system is (at least partially) offline.
How data is modelled
Data models are frequently normalized to minimize ambiguity. There are probably three different kinds of 500g bags of white bread, but each one will have a different product id, a different Universal Product Code, a different supplier... As it was mentioned in the section about relational databases, relations are as important as data: each item can be related to the corresponding supplier, an order, and batch in particular. Stores and warehouses have to be modelled as well to keep stock always at optimal levels. Disounts have to be modelled too, and they're particularly tricky because at some point the discount logic has to be applied at check-out.
Data models should be able to track every single item with the least possible ambiguity. If there's an issue with a product batch we should be able to locate with precision every single item and remove it from the shelves, and know exactly how many of those items were purchased. Any source of ambiguity requires manual intervention. For instance, it's possible that a store receives multiple batches with different times of expiry at the same time. In that case stockers have to make sure that the oldest batch is more visible in the shelves, put the newest batch at the bottom of the stack, and record when all items of each batch are sold or returned.
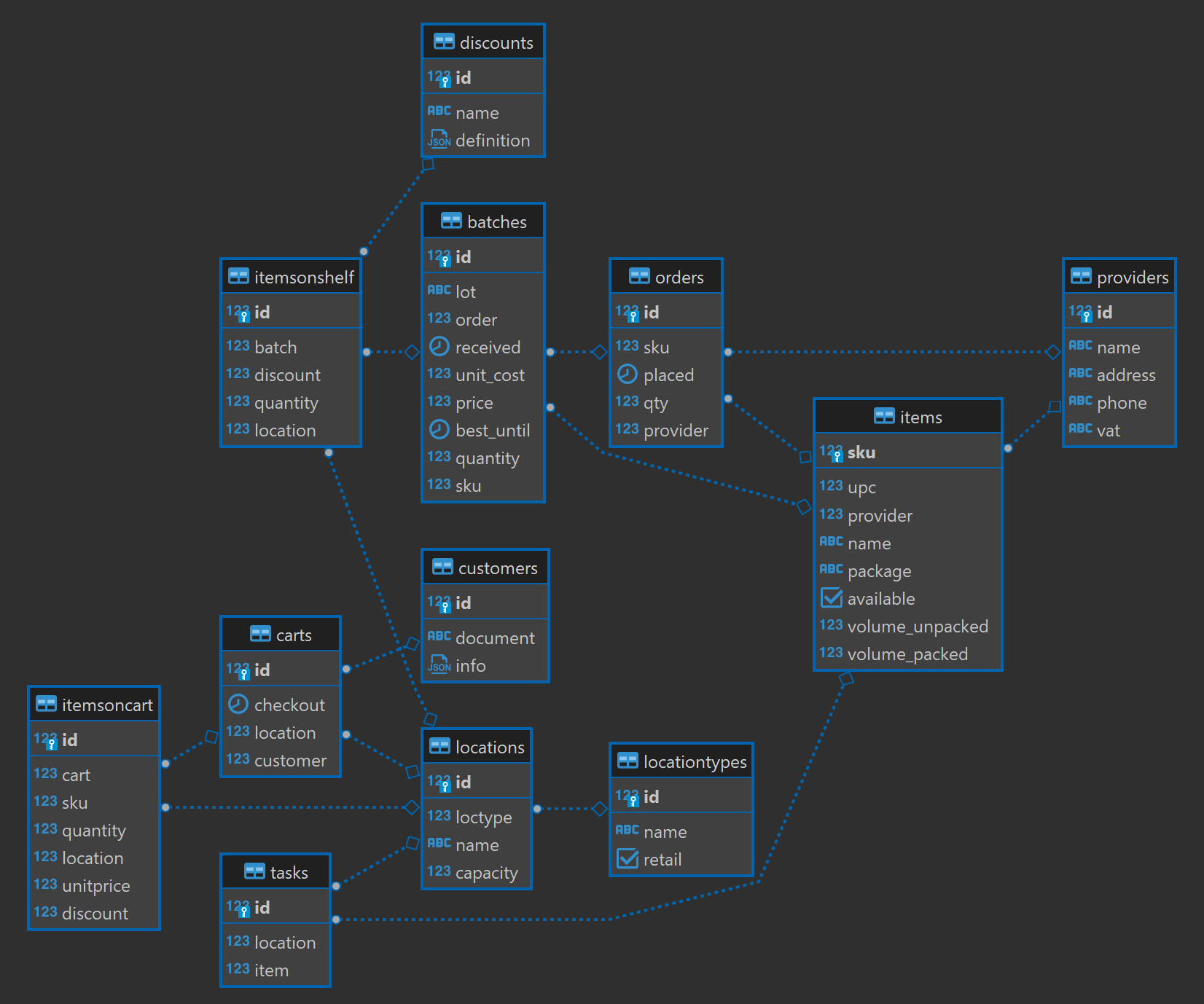
The digital twin has less than twenty data models, which is an extreme simplification of an actual retailer. This is the entity relational diagram, that may get outdated.
!!! tip
If you have to handle databases with dozens of normalized data models you should use a proper database management tool like [dbeaver](https://dbeaver.io/) or [datagrip](https://www.jetbrains.com/datagrip/).
The entity relational diagram above was generated by dbeaver.
Note how each model is related to a physical entity like an item, a batch, a cart, a location... Each table has a primary key that identifies a single record that is used to build relationships. For instance an item in a cart ready to check out is related to a cart, and a location.
Users, authorizations, and permissions
Probably the hardest feature to implement in enterprise contexts is access control, in other words, making sure that anyone who's supposed to see, add, remove, and delete some information can do it in practice, while blocking everyone else. Some change may require managerial approval, like changing the available stock of a particular item in a warehouse, in that case the system should issue the approval requiest to the correct person.
There are two main strategies to achieve this:
-
Access Control Lists (ACL), a set of rules in a database that implement the logic of who's allowed to see, add, remove, and delete what. In this strategy multiple users haveaccess the same applicaiton with a different role. Each object has a set of rules attached that are applied for every single operation. This is common in financial institutions where all customer-facing employees have access to the same terminal but each operation on each object requires different levels of authority. For instance, any employee may be able to see the balance of a customer, but not to approve the conditions of a mortgage. ACL tends to be so hard to implement that corporations seldom build their own solution, and by one from a popular vendor.
-
Instead of attaching rules at each data object, one can create a different application for each role. This is common in businesses where each worker works in a different location. Cashiers in a grocery store have access only to points of sale, stockers will have a handheld device with stocking information, managers will have access to a web application with privileges to return items, modify stocking information... In this case access control is implemented at a system level. Each one of those appliations will have its own authentication profile, and will be authorized to access a subset of API and other data resources.
None of these strategies is infallible and universal. The final implementation will probably be a mixture of the two. Workers in stores and warehouse may have role-specific terminals, while members of the HR department may have access to an ERP (Enterprise Resource Planning) that implements ACL underneath. Other common data operations like transfers, migrations, backups and audit logs may add more complexity to the final design. IT departments typically have full access to all data stored within the company, or parts of it, and while they can jump in to fix issues, they can break stuff too.
!!! example
Customer communications like emails are data too, and may be required by the regulator to investigate any suspicious behaviour. [JPMorgan had to pay a $4M fine](https://www.reuters.com/legal/jpmorgan-chase-is-fined-by-sec-over-mistaken-deletion-emails-2023-06-22/) to the regulator after a vendor deleted 47M emails from their retail banking branch. A vendor was trying to clean up very old emails from the '70 and the '80, that are no longer required by the regulator, but they ended up deleting emails from 2018 instead. In enterprise data systems some data models and resources have an *audit lock* property that prevents deletion at a system level.
The digital twin doesn't implement ACL, and each role will have a separate terminal instead.
!!! warning
Data access issues may be considered security threats if allow a user to escalate privileges. It's common for large corporations and software vendors to deploy red teams that to find these kind of vulnerabilities. There are also bounty programs intended to motivate independent security researchers to communicate these issues instead of selling them on a "black security market".
Governance: metadata management.
Data Governance is the discipline of providing the definitions, policies, procedures, and tools to manage data as a resource in the most efficient way possible. It's a very wide topic that involves managing both data and people. The goal is to create sustainable data environments that thrive as an integral part of the organization.
!!! danger
Beware of experts on data governance. There are orders of magnitude more experts on data governance on LinkedIn than successful implementations. I've witnessed talks about best practices on data governance from "experts" that were unsuccessful implementing them at their own company. From all experts, the most dangerous are the ones selling you the X or Y application that will get Data Governance sorted out for you.
The topic of data governance will be split in multiple sections across this case study. The reason for that is that Data Governance has to be implemented across the entire lifetime of the data, from its initial design to the dashboard that shows a handful of dials to the CFO. There's no silver-bullet technology that just implements Data Governance. It's the other way round, governance defines and enforces:
- Schemas are defined and documented, including standard patterns to name columns
- Who owns what, and which are the protocols to access, modify and delete each piece of data.
- How data transformations are instrumented, executed, mainained and monitored.
- In case something goes wrong, who can sort out what is going one, and who can fix it.
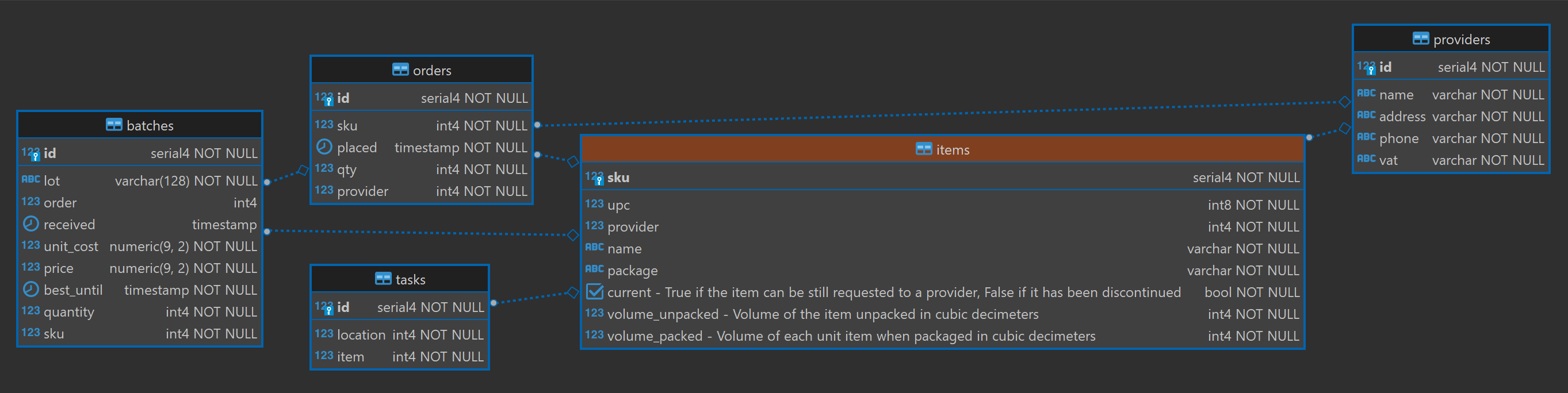
Let's talk a bit about point 1, which is related to metadata. Metadata is all the additional information that is relevant to understand the complete context of a piece of information. If a table has a field with the name volume_unpacked there should be one and only one definition of volume across all databases, and a single definition of what is an unpacked item. The same database that stores the data can store this additional information too. If the field volume in the item entity has units of liter. This is how the model Item is defined as a SQLAlchemy model:
class Item(Base):
__tablename__ = "items"
sku: Mapped[int] = mapped_column(primary_key=True)
upc: Mapped[int] = mapped_column(BigInteger, nullable=False)
provider: Mapped[int] = mapped_column(ForeignKey("providers.id"))
name: Mapped[str] = mapped_column(nullable=False)
package: Mapped[str] = mapped_column(unique=False)
current: Mapped[bool] = mapped_column(
comment="True if the item can be still requested to a provider, "
"False if it has been discontinued"
)
volume_unpacked: Mapped[int] = mapped_column(
comment="Volume of the item unpacked in cubic decimeters"
)
volume_packed: Mapped[int] = mapped_column(
comment="Volume of each unit item when packaged in cubic decimeters"
)
And this is how it's reflected in the ER diagram centered on the Items table:
Metadata management can be implemented as a data governance policy:
- All fields that could be ambiguous have to be annotated with a clear definition.
- These schemas can be published in a tool that allows anyone to search those definitions, and where those data are stored.
Point number 2 is more important than it seems, and its implementation is usually called "Data Discovery". There are tools like Amundsen (open source) or Collibra (proprietary) that implement data catalogs that you can connect to your data sources and extract all metadata they contain, and archive it to create a searchable index similarly to what Internet search engines do. Some organizations implement some simplified metadata management, and only the fields in the data warehouse (more on this later) are annotated. In this case they tend to use tools that are specific for the database technology like Oracle's data catalog
This allows you to make sure that every time the term sku is used it actually refers to a Stock Keeping Unit and the storage resource is using it correctly.
Bootstrapping the database
The first step is to create a new database in an existing postgresql database server with:
createdb -h host.docker.internal -U postgres retail
If you're using an ATLAS Core instance you may want to use a different database name.
The package includes a set of convenience scripts to create the tables that support the digital twin that can be accessed with the retailtwin command once the package has been installed. The init command will persist the schemas on the database.
retailtwin init postgresql://postgres:postgres@host.docker.internal/retail
And the bootstrap command will fill the database with some dummy data
retailtwin bootstrap postgresql://postgres:postgres@host.docker.internal/retail
After running these two commands a stocked chain of grocery stores will be available:
psql -h host.docker.internal -U postgres -c "select * from customers limit 10" retail
!!! success "Output"
```
id | document | info
----+----------+-------------------------------------
1 | 59502033 | {"name": "Nicholas William James"}
2 | 32024229 | {"name": "Edward Jeffrey Roth"}
3 | 40812760 | {"name": "Teresa Jason Mcgee"}
4 | 52305886 | {"name": "Emily Jennifer Lopez"}
5 | 92176879 | {"name": "Joseph Leslie Torres"}
6 | 60956977 | {"name": "Brandon Carmen Leonard"}
7 | 04707863 | {"name": "Richard Kathleen Torres"}
8 | 74587935 | {"name": "Emily Anne Pugh"}
9 | 78857405 | {"name": "James Rachel Rodriguez"}
10 | 80980264 | {"name": "Paige Kiara Chavez"}
```
Normalized data, functions and procedures
If data models are normalized many tables will include many references to other models. These are some of the contents of the model Itemsonshelf that contains the items that are available in one location in particular, and their quanity.
!!! success "Output (truncated)"
```
id |batch|discount|quantity|location|
---+-----+--------+--------+--------+
1| 1| | 31| 1|
2| 2| | 31| 1|
3| 3| | 31| 1|
4| 4| | 31| 1|
5| 5| | 31| 1|
6| 6| | 31| 1|
7| 7| 4| 31| 1|
8| 8| | 31| 1|
9| 9| 7| 31| 1|
```
This table only contains foreign keys and quantities are provided on a per-batch basis. Obtainig very simple metrics, like some location's current stock of an item in particular, requires joining multiple tables. This is why databases tend to bundle data and logic. Modern Database Management Systems (DBMS) are programmable and users can define functions and procedures to simplify queries and automate data operations. The query that gets the stock of an item in a given location can be expressed as a function in SQL as:
{!../src/retailtwin/sql/stock_on_location.sql!}
Functions can be called both as values and as tables, since functions may return one or multiple records:
select * from stock_on_location(1,1)
is equivalent to
select stock_on_location(1,1)
and both calls return the same result
!!! success "Output"
```
stock_on_location|
-----------------+
31|
```
This package contains a set of functions, procedures, triggers, and other helpers that can be recorded into the database with
retailtwin sync postgresql://postgres:postgres@host.docker.internal/retail